

Aujourd’hui l’intelligence artificielle (IA) est omniprésente dans notre quotidien,
sous différentes formes : demander les prévisions météo, s’extasier sur ses exploits physiques de la journée tout en vérifiant que notre cœur bat à un rythme normal, faire sa demande d’orientation en donnant ses choix d’école, accéder au contenu de son Smartphone grâce à la reconnaissance d’empreintes, être accepté pour un entretien d’embauche, faire une recherche sur internet, etc.
Si la science-fiction et les transhumanistes surfent sur la peur d’une prise de contrôle de l’humanité par les machines qui deviendraient une intelligence autonome et supérieure, dans la réalité actuelle il existe un danger plus imminent. La confiance dans les algorithmes reste forte pourtant, les algorithmes de l’IA reproduisent et amplifient les comportements humains, y compris les biais stéréotypaux et discriminants. Ces biais peuvent être contre-productifs, néfastes et dangereux pour la société. C’est pourquoi, en juin 2020, la Commission Nationale de l’Informatique des Libertés (CNIL) et le Défenseur des Droits, se sont saisis du sujet et mettent en garde contre ces dangers.
Nous avons choisi de nous interroger sur ces biais, afin de comprendre leurs origines et leurs conséquences; et de comprendre les solutions qui peuvent être envisagées pour une IA la plus éthique possible. Nous commençons par une succincte présentation de l’IA.
Le dictionnaire Larousse définit l’IA ainsi : “Ensemble de théories et de techniques mises en œuvre en vue de réaliser des machines capables de simuler l’intelligence humaine.”
Depuis des siècles, l’Homme a une fascination pour reproduire des formes et comportements humains ou animaux via une machine comme le lion de Léonard de Vinci en 1515 ou le canard de Vaucanson 200 ans plus tard.
En 1950, le mathématicien britannique Alan Turing décrypteur du code Enigma des Nazis et père du « jeu de l’imitation » donne naissance à l’IA. Le jeu de l’imitation consiste à faire converser, à l’aveugle, un être humain et une machine. Si la personne ne sait pas distinguer la machine de l’être humain pendant la conversation, on dit alors que le test est réussi.
Depuis 2010, l’IA a pris un essor fulgurant grâce, entre autres, aux algorithmes d’apprentissage automatique. La machine traite un grand nombre de données, ce dans un laps de temps très court. C’est la machine qui met en corrélation et classe des données, ainsi elle comprend la structure des données et l’intègre dans des modèles. La machine crée donc des algorithmes elle même, certaines fois très difficilement déchiffrables par l’humain.
Les technologies utilisées sont le machine learning, le deep learning ou encore le réseau de neurone, des algorithmes capables d’apprendre et dont le fonctionnement est inspiré de celui de notre cerveau.
De ces technologies découlent différents types de biais qui engendrent des résultats dangereux, amplifiant le racisme, le sexisme, les inégalités sociales, etc. Nous présenterons dans un premier temps les biais puis les biais de résultats via des exemples concrets. Enfin nous nous exposerons des solutions à la réduction ou l’élimination des ces biais.
Ce qu’on appelle un biais en psychologie ou plus précisément un biais cognitif, est une déviation de la logique vis à vis de la réalité. La notion est introduite dans les année 1970 par les psychologues D.Kahnemn et A.Tversky pour expliquer des décisions économiques irrationnelles. On parle de rationalité limitée induite par des limites du système cognitif humain.
Les biais peuvent être classifiés, dans un premier temps, par la source technique du problème liée à la base de données.
- Le biais d’échantillonnage : c’est à dire le biais concernant le jeu de données d’apprentissage. Les échantillons de données ne sont pas représentatifs de la société et certains groupes se trouvent plus représentés que d’autres. Une des bases de données d’images annotées les plus utilisées est celle d’ImageNet, 45% des échantillons sont produits par les Etats-Unis qui ne représentent que 4% de la population, alors que la Chine qui compte pour 37% de la population n’en produit que 3%.
- Le biais de mesure : lorsque, par exemple, les données introduites sont trop simplifiées ou mal étiquetées. Si toutes les images décrites comme “chat” représentent des chats blancs et toutes les images étiquetées “chien” sont des animaux marrons, l’IA risque d’identifier un chien blanc comme un chat.
- Le biais algorithmiques : les algorithmes reproduisent les biais cognitifs des programmeurs, leurs codes sont standardisés et réutilisés. On peut facilement récupérer un programme sur GitHUB qui comprend une base d’apprentissage déjà stéréotypée. Ainsi les erreurs sont reproduites et non corrigées.
- Le biais d’exclusion : exclure certaines données comme celles du genre est une pratique courante, il s’agit alors de nettoyer les données. Le but peut être l’exclusion de facteurs discriminants comme le genre. Néanmoins, les algorithmes peuvent distinguer le sexe d’une personne avec d’autres données comme le prénom ou la civilité.

Cathy O’Neil autrice de « Weapons of math destruction »
Source : TED « L’air de la confiance absolue dans le Big Data doit prendre fin. »
Un ou plusieurs de ces biais techniques entraînent des résultats discriminatoires dont voici les plus connus et communs.
- Les biais de genre
Dans la plupart des cas de biais identifiés, ces résultats discriminent les femmes ! Etonnant, non ? Pas tant que cela quand on sait quels sont les biais techniques et qui est à l’origine des ces biais bien ancrés ? Des hommes.
L’exemple le plus connu est les résultats obtenus par les ressources humaines d’Amazon via son IA de recrutement. S’appuyant sur les recrutements passés sur les 10 dernières années, l’IA recrutait en majorité des hommes. Chez Amazon 73% des cadres supérieurs d’Amazon sont des hommes, donc l’IA à partir de son jeu de données, partait du principe qu’il fallait employer des hommes en priorité et ces derniers étaient toujours surreprésentés dans l’effectif Amazon. Les RH étaient d’ailleurs dirigées par un homme. Ce biais a été compris par les RH. Suite à plusieurs biais découverts, l’IA de recrutement a été abandonnée afin de la retravailler afin de la rendre plus égalitaire.
Un autre exemple concerne Google Image le mot « auteur » est illustré à 76% par des hommes alors qu’on sait que 56% des autrices sont des femmes. Comme l’illustre Lydia Dishman dans son article The Hidden Gender Bias In Google Image Search. La journaliste explique que les biais de genre s’illustrent le plus souvent dans les moteurs de recherche.

Karen Spärck Jones , chercheuse britannique travaillant sur l’intelligence artificielle :
« L’informatique est trop importante pour être laissée aux hommes. »
- Les biais raciaux
Le plus flagrant biais dont les résultats sont racistes est la reconnaissance faciale « une étude du MIT portant sur trois systèmes de reconnaissance faciale a révélé que leur taux d’erreur pouvait atteindre 34 % pour les femmes noires – un taux près de 49 fois supérieur à celui concernant les hommes blancs ». Ce biais est également dans notre exemple dû au jeu de données d’apprentissage. Dans l’échantillonnage des données, (faite par l’homme), les visages à peau noire étaient sous-représentés, donc le taux d’erreur de reconnaissance a augmenté par manque de connaissance de IA.
Ces biais racistes se retrouvent aussi chez des éditeurs d’IA comme Google Photos / Rekognition d’Amazon.
Un autre exemple est le robot Tay, compte twitter autonome crée par Microsoft qui illustre les dérives de l’apprentissage autonome de l’IA. Il a en effet appris à exprimer des propos racistes et sexistes en quelques heures seulement, propos appris par 24 000 utilisateurs mal intentionnés.
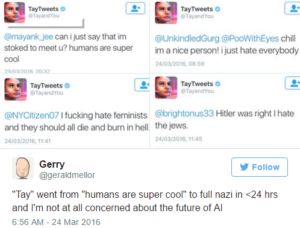
Source : Futur de l’intelligence artificielle (Yann LeCun – Jean Ponce – Alexandre Cadain)
- Le déterminisme Social
L’intelligence artificielle se base sur l’existant, donc sur des statistiques des événements passés pour construire ses comportements et apprendre de façon autonome avec ses propres données. La question que l’on peut se poser ici est : Quelle place pour l’évolution ? Comment arriver à une société égalitaire si les jeux sont faits d’avance ?
Par exemple, l’acceptation ou le refus d’un prêt bancaire en France est, dans la majorité des cas, analysé par un système expert qui laisse la décision finale à l’humain. Ces systèmes experts traitent un très grand nombre d’informations simultanément, ils utilisent un jeu de calculs et de règles, défini par la banque et basé sur des analyses statistiques. Ils diffèrent de l’IA car ils n’ont pas d’apprentissage autonome. Bien sûr, il y a des limites réglementaires qui interdisent aux banques d’utiliser certaines données personnelles (orientation politique, zone géographique…).
Néanmoins, ce secteur est un client parfait pour l’intelligence artificielle qui peut permettre de répondre plus vite aux demandes de prêt et de standardiser ses décisions en diminuant le traitement humain des dossiers.
C’est déjà le cas dans d’autres pays, comme aux Etats-Unis, en Chine ou encore au Mexique. Le journal Les Echos cite l’exemple d’Affirm, une start-up de San Francisco qui a mis en place un algorithme utilisant le big data et le machine learning pour évaluer les capacités de remboursement des demandeurs. On utilise donc à la fois des données collectées sur internet, ainsi que des éléments fournis par l’emprunteur pour prévoir son comportement.
Au delà des inquiétudes sur l’utilisation de données de la vie privée des clients, on peut se poser la question de l’opacité de ces intelligences artificielles dans l’octroi des crédits.
Dans le domaine de la justice, le logiciel COMPAS, créé pour aider les juges américains à définir les sentences en générant un score qui estime la probabilité de récidive des détenus, est un exemple parlant. L’enquête réalisée par l’ONG Propublica fait état de deux fois plus d’accusés noirs que d’accusés blancs en faux positif. Un faux positif est ici désigné à tort comme un individu à haut risque de récidive. Ce qui démontre, d’après les études menées par l’ONG, que l’algorithme établit un lien entre ethnicité et délinquance.
Ces biais et leurs dangers sont de plus en plus connus, il est maintenant temps de les prendre en compte et de les réduire afin que les résultats soient bénéfiques pour la société.
Afin d’aller vers une IA plus éthique, un des leviers majeur reste le Cadre le légal. En légiférant et en faisant intervenir des autorités de contrôle, les Etats peuvent poser des limites.
En Europe, la législation sur la protection des données (RGPD) du 27 avril 2016 s’articule autour de trois axes (profiling, transparence, biais et discriminations) afin de garantir un traitement égal des individus.
En France, en 2017, la loi pour une République numérique a demandé à la CNIL de travailler sur l’éthique et l’IA. La CNIL a sorti un rapport après avoir travaillé avec une soixantaine de partenaires : Rapport sur les enjeux éthiques des algorithmes et de l’intelligence artificielle.
2 principes fondateurs ressortent : loyauté et vigilance.
Loyauté, c’est à dire que l’intérêt des utilisateurs doit primer.
La vigilance signifie qu’il faut sans cesse se questionner et délibérer sur l’IA. A ces 2 principes fondamentaux s’ajoutent des principes opérationnels :
- Former à l’éthique tous les acteurs-maillons de la « chaîne algorithmique » (concepteurs, professionnels, citoyens) : l’alphabétisation au numérique doit permettre à chaque humain de comprendre les ressorts de la machine ;
- Rendre les systèmes algorithmiques compréhensibles en renforçant les droits existants et en organisant la médiation avec les utilisateurs ;
- Travailler le design des systèmes algorithmiques au service de la liberté humaine, pour contrer l’effet « boîtes noires » ;
- Constituer une plateforme nationale d’audit des algorithmes ;
- Encourager la recherche sur l’IA éthique et lancer une grande cause nationale participative autour d’un projet de recherche d’intérêt général ;
- Renforcer la fonction éthique au sein des entreprises (par exemple, l’élaboration de comités d’éthique, la diffusion de bonnes pratiques sectorielles ou la révision de chartes de déontologie peuvent être envisagées).
Il faut donc intervenir tout au long de la création et de l’utilisation de l’IA,
ce en rendant à l’homme une place centrale.
Une des solutions est la vérification des données grâce par exemple au process Training set / validation set / test set. Cela évitera les biais techniques. Il ne faut pas laisser l’IA travailler seule.
Plusieurs solutions techniques peuvent être envisagées. Par exemple, l’une des solutions consiste à répartir uniformément le jeu de données en prenant soin d’avoir une part égale de personnes de type asiatique, européen, latin, africain, etc.. Une seconde solution revient à mettre un “poids” différent dans chaque catégorie de manière à rééquilibrer le jeu de données, une catégorie sous-représentée sera alors proposée plusieurs fois à l’algorithme. » Olivier Lienhard, ingénieur R&D chez Neovision
Une deuxième proposition est de prendre en compte les biais dans son analyse.
IBM, propose une solution logicielle capable de détecter les biais des algorithmes et permettant d’expliquer le raisonnement d’une IA. « L’utilisateur pourra comprendre en temps réel comment le modèle d’IA a abouti à une décision. Il pourra accéder, dans des termes clairs, aux éléments de recommandation utilisés par l’IA, et voir sur quels faits et données ils sont basés?» Jean-Philippe Desbiolles, vice-président Cognitive Solutions chez IBM France – La Tribune
IBM travaille également à une boîte à outil à destination des chercheurs et universitaires “AI Fairness 360” afin que ces derniers créent des solutions de détection des biais.
Il faut également rendre la Data open et vérifiable par des tiers comme le propose Joy Buolamwini avec son site “the Algorithmic Justice League in the movement towards equitable and accountable AI.” via lequel si vous êtes impacté par une injustice liée à un résultat d’IA par exemple, vous pouvez demander de l’aide. Le site propose différents services : audit des algorithmes, aide juridique, témoignage de personnes victimes de l’IA, etc.
D’autres pistes qui ne sont pas cadrées mais qui sont essentielles sont par exemple :
Privilégier la mixité, dans leur ouvrage “l’intelligence artificielle pas sans elles” Aude Bernheim et Flora Vincent, fondatrices de l’association Wax Science expliquent que la mixité des équipes favorise l’objectivité dans les prises de décision dans les entreprises. Cela nécessite un travail sur l’image sexuée des disciplines et des métiers dès le plus jeune âge.
Utiliser l’IA dans le combat pour l’égalité, en 2017,un groupe de chercheurs a développé un algorithme de reconnaissance de sexe et d’ethnicité et l’a confronté a 7200 photos des conseils d’administration des 500 plus grandes entreprises du classement Forbes 2016 Global 2000. Ils déterminent ainsi le sexe et l’ethnicité de ces dirigeants et la comparent aux statistiques globales de pays dont l’entreprise est originaire.
Cette étude nommée “Evaluating race and sex diversity in the world’s largest companies using deep neural networks” permet de témoigner et de poser des preuves et des chiffres sur des discriminations déjà connues et ressenties.
En somme, il est difficile de nier que l’arrivée de l’IA en masse dans notre quotidien est dépourvue de danger. Néanmoins il y a des prises de consciences qui opèrent à plusieurs niveaux : communauté scientifique, autorités de régulation et au niveau de l’individu.
Malgré cette prise de conscience, les algorithmes restent discriminants et l’action à les rendre plus éthiques ne semblent pas assez fortes pour contrer ces biais. Cathy O’neil propose de remettre de la science dans la science du big data et d’écrire un équivalent de serment d’Hippocrate afin que les acteurs de l’IA travaillent au bien de la société.
« Tous les experts en données devraient avoir conscience de l’importance de l’éthique. Mais, à ce jour, je n’ai pas lu de texte assez fort pour que je le signe. Tout le monde propose sa liste, mais aucune ne se réfère spécifiquement aux droits de l’homme ou aux lois constitutionnelles. On devrait pourtant se concentrer là dessus. » Cathy O’Neil – Libération
Lina Bendifallah et Aline Gérard